Experiments
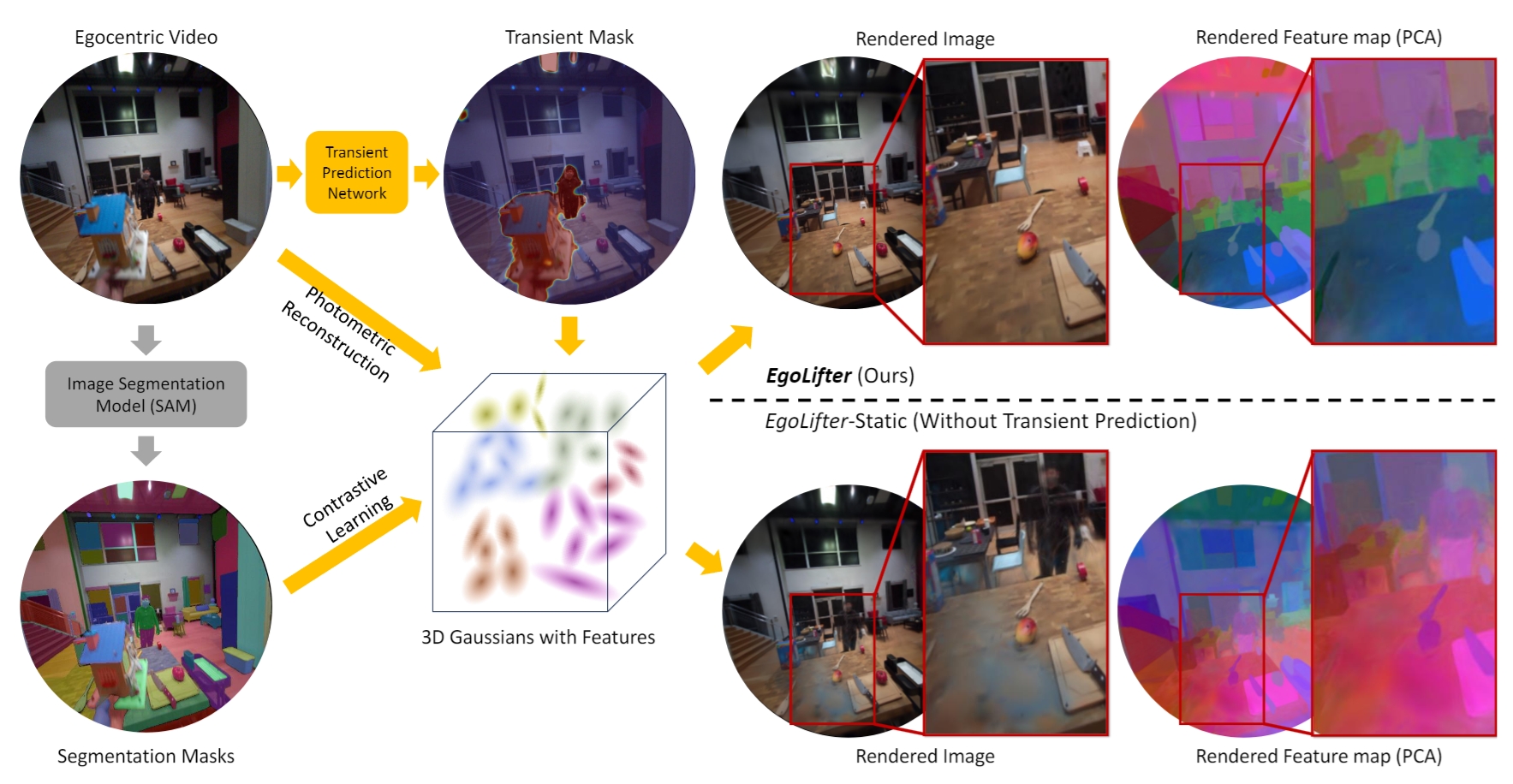
Egocentric videos capture frequent human-object interaction and thus contain a huge amount of dynamic motion with challenging occlusions. EgoLifter is designed to provide useful scene understanding from egocentric data by extracting hundreds of different objects while being robust to sparse and rapid dynamics.
To demonstrate this, we compare the following variants in our experiments:
- EgoLifter: Our proposed full method
- EgoLifter-Static: a baseline with the transient prediction network disabled. A vanilla static 3DGS is learned to reconstruct the scene.
- EgoLifter-Dynamic: a baseline using a dynamic variant of 3DGS, instead of the transient prediction network to handle the dynamics in the scene.
- Gaussian Grouping: a concurrent work that also learns instance features in 3DGS. However, Gaussian Grouping uses a video tracker to solve instance identities rather than contrastive learning.
Here are the qualitative results of EgoLifter on the Aria Digital Twin (ADT) dataset. Quantitative evaluation results and more analysis can be found in the paper. Note that baseline puts ghostly floaters on the region of transient objects, but EgoLifter filters them out and gives a cleaner reconstruction of both RGB images and feature maps.
Here is the qualitative comparison with Gaussian Grouping. Note that EgoLifter has a cleaner feature map probably because our contrastive loss helps learn more cohesive identity features than the classification loss used in Gaussian Grouping.